

Нужна идея игры, часть работы над которой, желательно рутинную часть, можно переложить на нейросеть, чтобы вместо Х месяцев разработки я бы завершил проект за Х/10 месяцев. Доверять код или геймдизайн – слишком рискованно, нужно было сделать что-то с бесконечным числом контента, который бы штамповал чатгпт. Самый простой, дешевый в производстве и легкий в исправлении контент – это нарративный контент, поэтому я взялся за текстовую игру.
Механика очень простая: нахождение слов из одной категории. По сути вся сложность это нагенерировать кучу категорий и слов в них. Я набросал пару категорий вручную и через три дня был готов прототип. Но все смотрелось уродски.
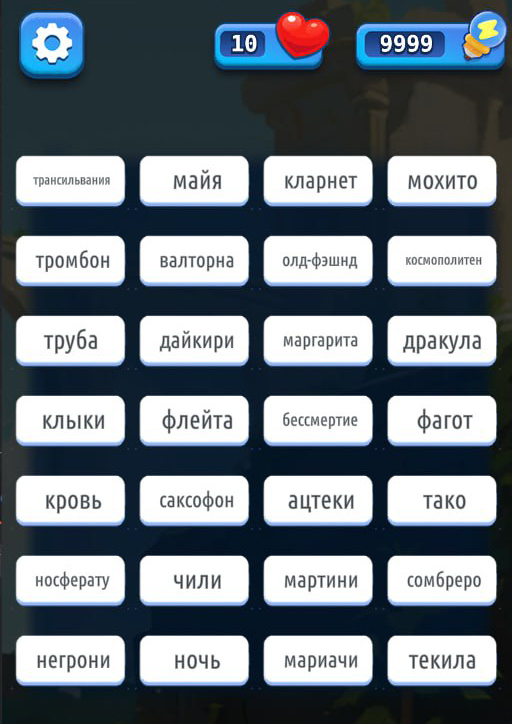
Так появились еще два логичных требования к словам: символов в слове должно быть до 10 и это должно быть одно слово. С исправленными условиями можно было использовать один размер шрифта на всех уровнях и не бояться, что слова будут выглядеть некрасиво.
Прототип готов, пришло время делать наполнение. Я поскреб по сусекам и нашел 400 иконок, которые могу использовать не нарушая прав. Вручную придумал разнообразные названия и начал спрашивать чатгпт слова для сформированных категорий:
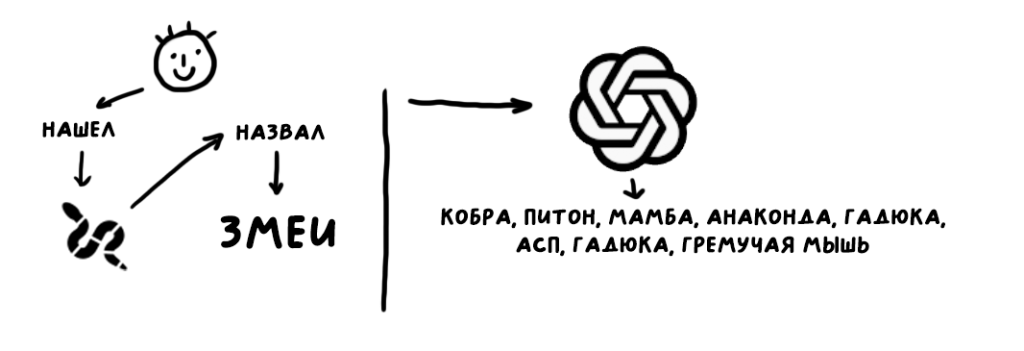
Дважды гадюка? Гремучая мышь? Как можно заметить по этой простой схеме в тот момент я еще улыбался, ведь не знал что меня ждет. Чатгпт после пары нормальных ответов жестко галлюцинировал. Править такие ответы конечно можно было, но это явно усложняло работу и прибавляло очень поехавшей рутины.
Пару раз менял промпты, условия, уговаривал его за деньги, угрожал, но результат все равно был не супер. После нескольких уточнений и допросов он исправлялся и хорошо генерировал змей, но плохо генерировал слова уже через один запрос. В этот момент нужно было решать нужен ли мне такой слегка отсталый помощник или нужно что-то менять или вообще бросить все и уйти в лес унабомбером. Мы с кодером были и без того туповатыми, а тут еще сверху тупая нейросеть, нет надо точно что-то делать. Надо как-то обучить его.
День ушел на поиск похожих игр и создание текстового файла формата категория – слова. Я создал бота внутри нейросети, скормил ему обучающие материалы, дал ему четкие инструкции.
Проверка.
Ассоциации он выдавал неплохие, но абсолютно не выполнял мои условия про то что слово должно быть одно и до 10 символов.

Я тюнил бота несколько дней, но подвижек не было. Тогда после подсказок я вернулся в обычный чат с ним и уговорил его перепроверять свои ответы питон скриптом, который он должен исполнять прямо в чате. Итоговый запрос выглядел примерно так:
Do the following steps for me:
provide me a list of words associated with the topic I specify
Check your list with a python script that each option you provide fits the following conditions:
-has only one word in it and the word isn’t longer than 9 symbols
-if resulted output is less than 20 words, repeat until result will be at least 20 words
-When you have 20 words re-check the list again for the conditions and make sure they fits the topic
give me answers in one line, separated with commas
If you understand what I want just request the topic
И это сработало. Точнее это было лучше всех запросов до. В легких категориях вроде стран и космоса он и правда выдавал то что мне нужно. Но как только было что-то сложное или точное он начинал жутко хитрить, обманывать, галлюцинировать. Например, так выглядели уговоры дать мне список произведений.


Рабочим вариантом для таких уровней стала последовательность действий, где я кидаю в чат тхт файл со списком из сотни произведений и тогда из этого файла он выбирал нужные.
Итак еще раз, алгоритм: спросить его где найти список по этой теме – перейти по ссылкам – сохранить все в тхт – вернуться и попросить поработать со списком. Вместо дня времени прошла неделя и я обнаружил себя в рабстве у робота, подстраиваясь под ее ответы и каждый раз допиливая промпты, которые будет выдавать нужный результат хотя бы в 60% случаев. Еще пару дней отрицания, гнева, торга и 300 категорий были готовы. Мозг плавился как суммарно не плавился за прошлые две игры. В каких-то категориях было 30 слов, в каких-то всего 4, это все надо было учитывать и пришло время писать генератор уровней.
Генератор уровней
Генератор уровней в казуальных играх чаще всего строится по одному и тому же принципу. Игроку на протяжении 5-6 уровней поднимают сложность, потом его ждет самый хардкорный уровень и дальше плато, где он отдыхает после прохождения сложного уровня. Затем все повторяется.
Ок, а что такое сложность в игре такого типа? Какие уровни считать сложными?
Я отталкивался от самого простого подхода, где размер уровня напрямую влияет на его сложность. Т.е. уровень 4 на 4 легче, чем 4 на 8. Второй параметр который влиял бы на сложность это количество категорий в одном уровне.
Это значит генератор первой версии принимает в качестве аргумента два параметра: размер уровня и число категорий. Мы составляем композицию из слагаемых равную числу категорий. Например,
уровень 4 на 4 на 3 категории может быть: 4 Х 4=16=5+5+6=4+8+4=7+5+4=… (т.е. это может быть 3 категории по 5 слов, 5 слов и 6 слов и т.д.)
На глаз число слов в одной категории должно быть от 4 до 8, так что итоговое число композиций не такое и большое. Я накидал первую тысячу уровней, получил композиции, затем под каждое слагаемое взял слова из категорий и попробовал поиграть. Вышло плохо.

Проблем было много, нужно сделать вторую итерацию генератора.
Сделал так чтобы на одном уровне не было похожих категорий (типа женские и мужские имена, завтраки и фрукты и т.д.), сделал так чтобы категория или слова повторялись минимум через 25 уровней (ну скучно же играть снова в похожее) и попытался сделать так, чтобы слова распределялись на 1000 уровней примерно одинаково.
Все равно игралось плохо.
Например, слово “банан” в моем словаре, откуда я брал все это входило сразу в 5 категорий вроде желтая еда, африка, фрукты, корм для животных, а слово “дирижабль”, входило всего в одну категорию и при этом этот алгоритм делал так, чтобы они встречались одинаковое число раз на 1000 уровней. Это условия я убрал.
Некоторые слова писались одинаково, но были частью разных категорий как например ring может относиться к свадьбе и одновременно боксу. Мне пришлось переделать логику, добавить еще пару усложнений генерации, но все равно игралось плохо. На первых уровнях всплыло слово “паритет”, а я ожидал чего-то вроде “яблоко”, “собака”. Нужно было как-то учитывать сложность самих слов.
Чтобы автоматизировать все, я пошел на хитрость и решил воспользоваться словарями существительных. Например, в первых уровнях, которые должен пройти первоклассник слова должны быть очень простые, например из туристического словаря на первые 1000 существительных.
Я попробовал этот словарь и оказалось что в категориях осталось по 1-2 слова. Например “апельсин”, уже не было в этом словаре. Ок, значит проблема в словаре? Берем словарь на 10 тысяч слов и там нет слова киви и авокадо (столбик F слова которые не нашлись в словаре, а в E – то что нашлось).

Похоже проблема все еще в словаре, так же?
Я скачал все до чего дотянулся.
Частотные словари основанные на новостях и книгах на 40 тысяч слов содержали в себе кучу ненужных слов, а вот “скейтборда” в них не было.
Словари для spellcheckerов или для игры в Эрудит или словари скомпилированные из названий статей википедии содержали СЛИШКОМ много слов, в них буквально входили все слова из моей игры + такие, что я видел впервые в жизни.
Еще пара частотных, пара туристических и на пятнадцатом словаре было очевидно, что пора менять сам подход. Время ручной работы? Все же 300 категорий. Делим слова внутри каждой категории на 3 сложности, основываясь на внутреннем ощущении сложности слов (яблоко, груша, банан – фейхоа,дуриан – питайя, гуава).
Где-то на 70й строчке я понял, что это слишком безумно и усложнит генератор в разы т.к. нужно будет придумать коэффициенты к этим сложностям, поэтому надо взять себя в руки и первые 50 уровней буквально отобрать вручную, выкидывая все сложное. После 50го уровня будущий игрок для меня становился эрудитом и там уже работал генератор выдавая любые слова без сортировки.
Ну что, вот и все, игра готова, игралась неплохо, мы залили ее с тремя языками, которые я знал: украинским, английским и русским. Видеотест на 20 людях из разных стран.
Когда человек знал язык то играл дольше 9 минут, а когда не знал, то бросал на этапе туториала. Что конечно ожидаемо и логично, но как можно не пройти туториал?
Ух, похоже время следующей части.
Перевод
Перевод – неприятная, сложная, скользкая тема. Если можно отдать кому-то, заплатить или тебе помогают с этим – я всегда соглашаюсь. В данном случае перевод стоил приблизительно от 700 до 2к долларов за язык, что как бы сильно увеличивало стоимость разработки игры, которая до этого момента развивалась по модели ramen profitable. Переводить нужно самому, но при этом из того что я уже знаю на своем опыте к этому моменту: чатгпт подводит, гуглтранслейт подводит, deepl подводит.
Нужно как-то объединить все три технологии и проверить насколько удобоваримые результаты выходят. Поскольку я не знаю больше трех языков, нужно составить алгоритм базируясь на двух языках, а затем сравнить его с контрольным, который я не использовал.
Я выбрал украинский и английский, с ними я буду работать, а после проверю с контрольным русским.
Перевожу в Google Sheets сразу двумя переводчиками (гуг переводчик бесплатно, deepl бесплатно до полумиллиона символов). Перевожу с английского на русский гуглом, с украинского на русский гуглом, с английского на русский диплом и с украинского на русский диплом.
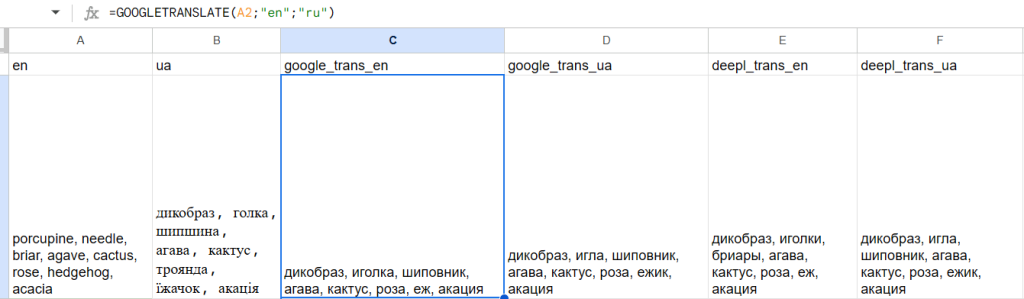
Даже на примере выше видны проблемы. Появляется несколько переводов одного слова (игла, иголки), так же появляется проблема c переводом одного из терминов (briar). Так же иногда некоторые термины при переводе становятся больше 9 букв, например кузница – blacksmith, такое тоже выкидываю.
Поэтому дальше я поступаю так: беру только те слова, которые во всех столбцах совпадают и в них до 10 букв и они состоят из одного слова, а до нужного количества добиваю с помощью ChatGpt.
Тут стоит уточнить, что работать с Google Sheets долгое время было очень приятно. Пишешь в одной ячейке что нужно переводить, в другой пишешь запрос =GOOGLETRANSLATE(A2;”en”;”ru”) и оно переводит гуглпереводчиком, в третьей пишешь =DeepLTranslate(A2;”en”;”ru”) и оно переводит Deeplом, в следующей формируешь запрос к ChatGpt с помощью плагина для гуглшита и оно прямо без чата за 10 минут тебе обрабатывает 300 столбцов. Круто же? Но почти за все надо платить: гуглпереводчик бесплатный, deepl бесплатный первые 500к символов, а чатгпт стоит 25 баксов в месяц + деньги за каждый запрос по апи (т.е. за каждую ячейку гуглщитс) + как оказалось деньги за пользование плагином.
Поскольку для меня это больше одноразовая акция, а не регулярная работа, поэтому я скачал себе табличку в виде xlsx файла, написал короткий питон скрипт, который работает с файлом и для каждой строки с помощью промпта, что писал в начале добивает слова до нужного количества, обращаясь по апи к нейросети.
Итого для того что я писал выше: дикобраз, агава, кактус, роза, акация -эти слова есть в каждой ячейке, а 3 слова пришли от чатгпт.
Проверяю еще на 15 ячейках – вроде рабочая схема, которая меня устраивает.
Отлично, переводим на другие языки. Тут chatgpt снова пытается меня объегорить.
Он генерирует слова, чтобы не было дубликатов с теми что уже переведены, но жутко хитрит. Слово champ есть? Ну так нет слова champion. О есть latte, ну так нету latté. Ты написал halva, но нету halwa.
Т.е. нужно написать скрипт который после получения данных от нейросети еще раз пройдется по этим данным, удалит дубликаты и снова сгенерирует слова. Но и тут есть проблема. Каким-то чудом на какой-то строке абсолютно случайно он ломается и выдает херню. Т.е. 100 ячеек он обрабатывает нормально, а на 101й выдает дичь. Кстати обратите внимание что ответ он пытается сформулировать каждый раз иначе, не смотря на то что почти всегда это одна и та же фраза.
Последняя проблема была в самих переводчиках, например водоемы: fjord, lake, ocean, spring, river, stream, pond они не восприняли целиком и переводили spring не как ручей, а как весна, из-за этого я добавил еще один промпт в самом конце на проверку и соответствие категориям. Итого схема примерно такая:
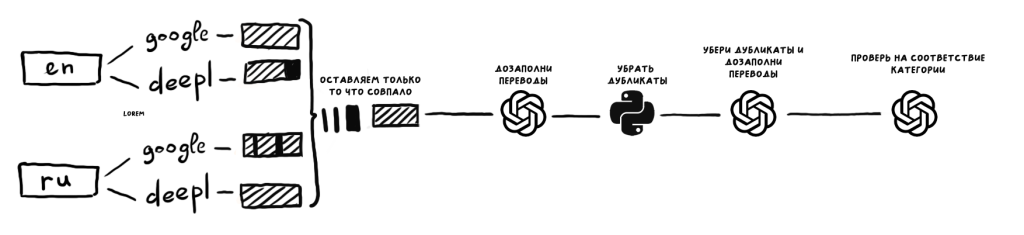
Так, с переводом справился, теперь осталось чуть напрячься и внести немного локальности в каждый перевод.
Художники, писатели, имена, названия городов и еще 30 категорий – все это можно чуть лучше локализовать, добавить для итальянцев больше итальянских писателей, для немцев больше немецких футболистов и т.д.

В самом конце ради эксперимента и под выход новой версии ChatGpt4o пробую еще одно свое предположение для генерации слов в категории, вдруг можно будет наделать новых с легкостью. Заливаю частотные словари и прошу найти слова для категорий именно из этого словаря. С какими-то он справляется очень даже неплохо:

Но на еде желтого цвета уже ломается и выдает: желтение (yellowing), желтизна (yellowness),желтозём (yellow earth), жёлудь (acorn), желток (yolk), жёлтый (yellow), лимон (lemon), банан (banana), кукуруза (corn), лимонное дерево (lemon tree).
Итог пока такой: доверять чатгпт точно нельзя, использовать его в самых простых вопросах можно только найдя нормальный промпт, как рутинный помощник он очень неплох тем, что не устает и выдает бешенное количество полуправильной информации за очень скромные деньги. Т.е. правильно настроив систему можно стать всего лишь поверяльщиком, что сильно сокращает конечное время работы. Но в итоге для продакшна чат гпт сейчас ближе всего к вайбер чату пгт. Я все так же верю, что кто-то успешно нашел способы применить чатгпт. Но я не ищу области где он работает. Я пытаюсь понять как сделать, чтобы он работал в моей области.
С удовольствием окажусь неправ, если кто-то мне приведет промпт, который выдаст книги русских писателей из одного слова.